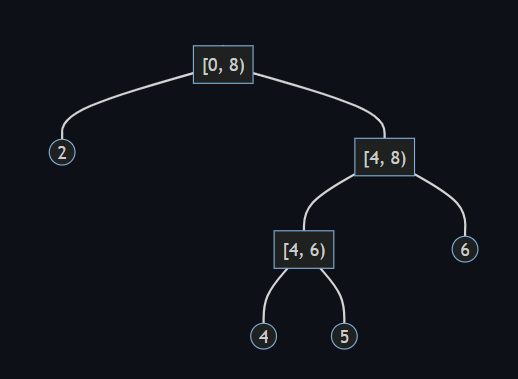
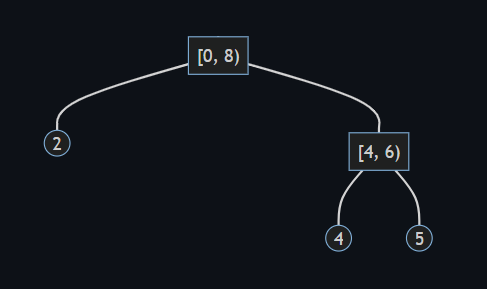
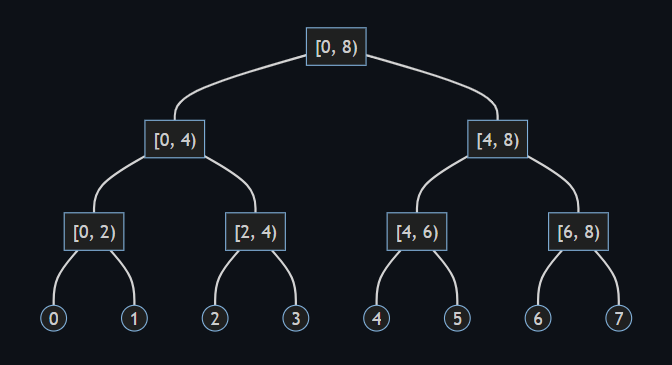
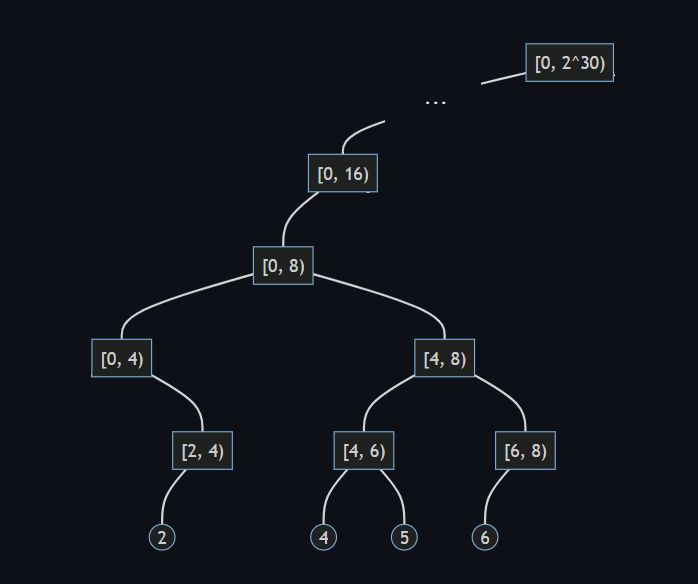
重み平衡二分木 (weight-balanced binary trees) を C# で実装したライブラリ WBTrees (GitHub) の初版 v1.0 をリリースしました。
主な機能は次の通りです:
(1) インデックスによる操作 (取得・更新・挿入・削除) をすべて  時間でできる List
時間でできる List
(2) インデックスによる操作 (取得・削除) もすべて 時間でできる Set, Map
WBSet<T>, WBMultiSet<T>, WBMap<TKey, TValue>, WBMultiMap<TKey, TValue> クラス- 通常の平衡二分探索木に、インデックスによるアクセス機能を追加したもの
- 二分探索により、要素からインデックスの取得もできる
- 安定ソート
WBMultiSet<T> および WBMultiMap<TKey, TValue> はキーの重複を許可する。したがって、両端優先度付きキュー、または安定ソートの優先度付きキューとしても使える
(1) の List と (2) の Set, Map はともに、内部構造としては重み平衡二分木 (weight-balanced binary trees) です。
ここでいう「重み」とは、部分木に含まれるノードの個数 (サイズ) を指し、この実装における Node<T> クラスの Count プロパティに相当します。
高さ平衡 (height-balanced) の二分探索木である AVL 木に対し、重みを利用することで自己平衡 (self-balancing) と「インデックスによる二分探索」の両方を実現します。
なお、Wikipedia の Weight-balanced tree によると「weight-balanced binary trees」という用語は平衡二分探索木 (self-balancing binary search trees) の一種として定義されています。
一般に、二分探索木という場合にはソート済みの制約が付けられた二分木を指し、この制約により「要素による二分探索」が可能となります。
上の Wikipedia の記事もその制約を前提として書かれているようですが、実際にはソート済みではなく「要素による二分探索」が可能でない実装もあり得る、というのが本ライブラリの主張です。
そこで、ここでは単に、重み平衡二分木 (weight-balanced binary trees) は、重みによる自己平衡機構を持つ「二分木」であると定義します。
すると、このデータ構造は「インデックスによる二分探索」が 時間でできるという性質を持ちます。
このうち「要素による二分探索」の機能を持たないものが (1) の List、持つものが (2) の Set, Map です。
さらに、自己平衡機構と「インデックスによる二分探索」の議論は分解できます。
すなわち、サイズ付き二分木 (sized binary trees) は、各ノードが重み (サイズ) を保持する二分木であると定義します。
するとこのデータ構造は、高さが  のとき「インデックスによる二分探索」が
のとき「インデックスによる二分探索」が  時間でできるという性質を持ちます。
これが何らかの自己平衡機構を持てば 時間となることが保証されます。
したがって、AVL 木や赤黒木 (二色木) など、従来の平衡二分木の構造をベースにしたリストの存在も考えられます (ただし多くの場合、各ノードが保持する情報量は増えるでしょう)。
実際、AVL 木によるリストについては動作確認済みです。
時間でできるという性質を持ちます。
これが何らかの自己平衡機構を持てば 時間となることが保証されます。
したがって、AVL 木や赤黒木 (二色木) など、従来の平衡二分木の構造をベースにしたリストの存在も考えられます (ただし多くの場合、各ノードが保持する情報量は増えるでしょう)。
実際、AVL 木によるリストについては動作確認済みです。
次の表は System.Collections.Generic.List<T> と WBList<T> の時間計算量の比較です:
| 操作 |
List<T> |
WBList<T> |
| Get by Index |
O(1) |
O(log n) |
| Set by Index |
O(1) |
O(log n) |
| Remove by Index |
O(n) |
O(log n) |
| Insert by Index |
O(n) |
O(log n) |
| Prepend |
O(n) |
O(log n) |
| Add |
O(1) |
O(log n) |
| Get All |
O(n) |
O(n) |
次の表は System.Collections.Generic.SortedSet<T> と WBSet<T> の時間計算量の比較です:
| 操作 |
SortedSet<T> |
WBSet<T> |
| Get by Item |
O(log n) |
O(log n) |
| Remove by Item |
O(log n) |
O(log n) |
| Add |
O(log n) |
O(log n) |
| Get by Index |
O(n) |
O(log n) |
| Remove by Index |
O(n) |
O(log n) |
| Get Index by Item |
O(n) |
O(log n) |
| Get All |
O(n) |
O(n) |
List に対する Add は「末尾に追加する」を意味し、Set に対する Add は「順序を保つように追加する」を意味することに注意してください。
バージョン情報
パッケージ
WBTrees は .NET プラットフォーム向けにビルドされ、NuGet Gallery にパッケージが発行されています。
ターゲット フレームワークは次のように設定されています:
これら以降のバージョンがサポートされます。
.NET Standard 2.0 は .NET Core 2.0 や .NET Framework 4.6.1 などの多くの環境を含んでいます。
詳細は .NET Standard で確認できます。
(競技プログラミング向け)
競技プログラミングでは NuGet を使えないため、ソースコードを単一のファイルにまとめたものを downloads で入手してください。
WBTrees のソースコードは C# 7.3 で書かれています。これは .NET Standard 2.0 に対応する C# のバージョンであるためです。
ただし、AOJ の環境である Mono 6.10 で動作させるために、一部の機能を使っていません。
他の言語への移植も歓迎します。
使用例
このライブラリの使い方は Usage (Wiki) に書かれています (まだ完全に網羅できていませんが)。
以下では、そのうち特徴的なものを挙げていきます。
まず、WBTrees 名前空間の using ディレクティブを追加します。
using System;
using System.Collections.Generic;
using System.Linq;
using WBTrees;
(1) List
WBList<T> の基本的な使い方は通常の List<T> に近いです。
挿入または削除が 時間で済むことによる利点が生きる場面で使うとよいでしょう。
var list = new WBList<int>();
list.Initialize(Enumerable.Range(0, 100));
list.Prepend(123);
list.Add(-234);
list.Insert(3, 345);
list.RemoveAt(5);
var item = list[7];
list[9] = 456;
var items = list.GetItems(20, 30).ToArray();
(2) Set, Map
WBSet<T> の基本的な使い方は SortedSet<T> に近いです。
同様に、WBMap<T> の基本的な使い方は SortedDictionary<T> に近いです。
要素による二分探索でノードを取得するには、条件を指定して GetFirst または GetLast メソッドを呼び出します。
例えば GetFirst であれば「指定された条件を満たす最初のノード」を取得することができます:
var set = new WBSet<int> { 4, 1, 5, 9, 2 };
var f1 = set.GetFirst(x => x >= 2).Item;
var f2 = set.GetFirst(x => x > 2).Item;
var l1 = set.GetLast(x => x <= 2).Item;
var l2 = set.GetLast(x => x < 2).Item;
var f3 = set.GetFirst(x => x > 9);
var l3 = set.GetLast(x => x < 1);
Remove*** メソッドも Get*** メソッドと同様に、Node<T> オブジェクトを返します。
null は、指定された条件を満たす要素が存在しないことを意味します。
同様にして、要素による二分探索でインデックスを取得できます。
例えば GetLastIndex であれば「指定された条件を満たす最後のインデックス」を取得することができます:
var set = new WBSet<int> { 4, 1, 5, 9, 2 };
var fi1 = set.GetFirstIndex(x => x > 2);
var li1 = set.GetLastIndex(x => x < 2);
var fi2 = set.GetFirstIndex(x => x > 9);
var li2 = set.GetLastIndex(x => x < 1);
インデックスを指定してノードを取得または削除するには、GetAt または RemoveAt メソッドを呼び出します:
var set = new WBMultiSet<int> { 3, 1, 4, 1, 5, 9, 2, 6, 5 };
var item = set.GetAt(6).Item;
var node = set.GetAt(-2);
var removedItem = set.RemoveAt(8).Item;
var items = set.GetItems(1, 4).ToArray();
また、Node<T> および Node<KeyValuePair<TKey, TValue>> に対しては拡張メソッドを用意しています:
var map = new WBMap<int, int>
{
{ 3, 1 },
{ 4, 1 },
{ 5, 9 },
{ 2, 6 },
};
var value5 = map[5];
var value6 = map.Get(6).GetValueOrDefault(-1);
while (map.RemoveFirst().TryGetValue(out var value))
{
}
問題集
List が使える競技プログラミングの問題:
Set, Map が使える競技プログラミングの問題:
参照
履歴
- 2022.03.22 その他の平衡二分木によるリストの実現可能性について追記
- 2022.05.17 重み付き (weighted) をサイズ付き (sized) に変更